Handling Multiple Obsidian Vaults on iOS
I use Obsidian to take notes for both work and personal stuff, and I use two separate vaults to keep the things a bit separate. In particular on the phone that's an extra few taps to switch between the vaults, which would leave me with notes in the wrong vault occasionally.

Only now I recognized that Obsidian supports Apple's Shortcuts app: The Open Obsidian action allows you to specify which vault to use. welcome to the two Obsidian icons on my homescreen – one for work, one for personal.
In-Range Dependency Updates with Renovate
Renovate is a tool to keep dependencies up-to-date in your software development projects. By default it is very eager to update dependencies regardless of defined ranges. This way you can avoid that updates keep pilling up.
I have a few internal packages that are actively hardened in different, parallel software releases. To better align for different teams working on those, different minor versions are being tracked per software release. For example productA relies @internal/package@1.3.x for an ongoing release, and productB tracks @internal/package@1.4.x. And to increase complexity newer features already land in the @internal/package@1.5.x versions.
I want the updates to be automatically distributed to keep manual efforts and overhead low. Enter renovate: Whenever a new version of @internal/package is built, a pipeline running renovate is triggered to update all consumers.
In short I'm aiming to get these changes from renovate:
# package.json
- "@internal/packageA": "~1.3.3",
+ "@internal/packageA": "~1.3.4",
# package-lock.json
# "node_modules/@internal/packageA": {
- "version": "1.3.3",
+ "version": "1.3.4",
With the base recommended rules from renovate, it would ignore an update on the 1.3.x branch and directly update to the latest 1.5.x version. So I dove deeper into the options how to solve this with renovate.
rangeStrategy: 'in-range-only' is not sufficient
The config parameter rangeStrategy does offer a way to handle only in-range updates: in-range-only. This will update the package in the package-lock.json only.
However this is not ideal in my use-case because some of the consuming packages themselves are a dependency in another project. So this update might get lost as only the data from the package.json is used to resolve the appropriate versions.
Solution: Individual rules with matchCurrentValue
So I needed to go a level deeper and trigger individual update rules based on the currently tracked version. This can be done with matchCurrentValue which contains the actual string from the package.json.
Here a full example to have patch updates for tilde-ranges, and minor and patch updates for caret-ranges:
// `config.js` for a self-hosted renovate setup to only update the `@internal/package`
// triggered from pipelines whenever a new version of `@internal/package` has been published
module.exports = {
// ... standalone config
repositories: [
{
// ... repository config
enabledManagers: ['npm'],
major: { enabled: false },
minor: { enabled: false },
patch: { enabled: false },
rangeStrategy: 'bump', // ensures that entries in the `package.json` is being updated
separateMinorPatch: true, // otherwise renovate would not track updates to patch versions,
// if also a new minor exists
packageRules: [
{
// disable all dependencies
enabled: false,
matchDepTypes: ['devDependencies', 'dependencies', 'peerDependencies'],
matchPackagePatterns: ['*'],
matchUpdateTypes: ['minor', 'patch', 'bump']
},
{
// Allow minor and patch updates for caret-ranges, e.g. `^1.3.0`
enabled: true,
matchDepTypes: ['devDependencies', 'dependencies'],
matchPackageNames: ['@internal/package'],
matchUpdateTypes: ['minor', 'patch'],
// RegExp to cover all version strings starting with a caret
matchCurrentValue: "/^\\^/"
},
{
// Allow patch updates for tilde-ranges, e.g. `~1.2.0`
enabled: true,
matchDepTypes: ['devDependencies', 'dependencies'],
matchPackageNames: ['@internal/package'],
matchUpdateTypes: ['patch'],
// RegExp to cover all version strings starting with a tilde
matchCurrentValue: "/^~/"
}
]
}
]
}With automerge enabled and renovate triggered once a new version of @internal/package is published, this removes pretty much any manual involvement. So we can rely that after a few minutes the changes will automatically land in the consuming project. 🚀
OpenCore Legacy Patcher
Turns out macOS Sonoma dropped the support for my 2017 MacBook Pro. Fiddling around with my setup in general, I decided to go for the upgrade nonetheless.
So, I gave the OpenCore Legacy Patcher a shot – a tool that patches macOS to work on older hardware. It worked much smoother than I expected, and I haven't noticed any issues in the past few days.
Overriding macOS Diagnostics Shortcuts
This is an addition to the last post on the Hyper Key and Shortcuts. There are a few shortcuts from macOS that already make use of the Hyper Key:
cmd + option + ctrl + shift + .: Will run the system diagnostics on macOS. This will use up resources from your system and also waste a lot of disk space in/var/tmpcmd + option + ctrl + shift + ,: Will open the most recent system diagnose in the Finder.cmd + option + ctrl + shift + w: Will run the Wi-Fi diagnostics – also using a lot of space.
An Apple StackExchange Thread helped me figure this out. Causing my manually defined shortcuts to fail inconsistently. But I wasn't able to find a way to disable this in macOS directly.
But I found a workaround: Assigning these key combinations to the f17 - f19 keys. 🎉 Those are in general not used by macOS, and so far, I didn't run into any complications.
Below the relevant part of my karabiner config:
{
"description": "Map Command-Shift-Option-Control-Period to f19 (avoid System Diagnostics)",
"manipulators": [
{
"from": {
"key_code": "period",
"modifiers": {
"mandatory": [
"left_command",
"left_control",
"left_option",
"left_shift"
]
}
},
"to": {
"key_code": "f19"
},
"type": "basic"
}
]
},
{
"description": "Map Command-Shift-Option-Control-Comma to f18 (avoid System Diagnostics)",
"manipulators": [
{
"from": {
"key_code": "comma",
"modifiers": {
"mandatory": [
"left_command",
"left_control",
"left_option",
"left_shift"
]
}
},
"to": {
"key_code": "f18"
},
"type": "basic"
}
]
},
{
"description": "Map Command-Shift-Option-Control-w to f17 (avoid Wifi Diagnostics)",
"manipulators": [
{
"from": {
"key_code": "w",
"modifiers": {
"mandatory": [
"left_command",
"left_control",
"left_option",
"left_shift"
]
}
},
"to": {
"key_code": "f17"
},
"type": "basic"
}
]
}Hyper Key and Shortcuts
When I researched the whole keyboard topic, I quickly stumbled over Karabiner Elements: A tool to customize the keyboard handling in macOS. I put it to use to remap the right ctrl key to option to fix that Keychron K2 flaw. But looking a bit more into it, quickly led me to the idea of a Hyper Key: Effectively this means mapping caps_lock (or any other key you don't need) to simulate the hold of essentially all modifiers (ctrl, option, command and shift). Then you can use this key in all sorts of other tools to define easy to reach keyboard shortcuts without having to be a finger acrobat.
In my current setup I use it to move windows around, to use ijkl as arrow keys, to launch all kind of tools and programs. This is a summary of my current system and the most important configurations in Karabiner Elements. You can add most of these snippets to your ~/.config/karabiner/karabiner.json under $.profiles.complex_modifications.rules.
Caps Lock as Hyper Key
I have been using caps_lock as esc ever since I got a MacBook Pro with a touchbar. First step for me was to undo this in the Keyboard settings of macOS, to have a sane default state.
To start off I added the default Change caps_lock to command+control+option+shift modifications. Additionally, I added a rule to use caps_lock as esc when it's pressed alone:
{
"description": "Change caps_lock to command+control+option+shift.",
"manipulators": [
{
"from": {
"key_code": "caps_lock",
"modifiers": {
"optional": [
"any"
]
}
},
"to": [
{
"key_code": "left_shift",
"modifiers": [
"left_command",
"left_control",
"left_option"
]
}
],
"to_if_alone": [
{
"key_code": "escape"
}
],
"type": "basic"
}
]
}Use i,j,k,l as Arrow Keys
Moving my hand from the home row down to the arrow keys is probably a movement I do way to often. Now I can use the
hyper + iasuphyper + jaslefthyper + kasdownhuper + lasright
{
"description": "Change hyper+jikl to arrow keys",
"manipulators": [
{
"from": {
"key_code": "j",
"modifiers": {
"mandatory": [
"left_command",
"left_control",
"left_option",
"left_shift"
],
"optional": [
"any"
]
}
},
"to": [
{
"key_code": "left_arrow"
}
],
"type": "basic"
},
{
"from": {
"key_code": "k",
"modifiers": {
"mandatory": [
"left_command",
"left_control",
"left_option",
"left_shift"
],
"optional": [
"any"
]
}
},
"to": [
{
"key_code": "down_arrow"
}
],
"type": "basic"
},
{
"from": {
"key_code": "i",
"modifiers": {
"mandatory": [
"left_command",
"left_control",
"left_option",
"left_shift"
],
"optional": [
"any"
]
}
},
"to": [
{
"key_code": "up_arrow"
}
],
"type": "basic"
},
{
"from": {
"key_code": "l",
"modifiers": {
"mandatory": [
"left_command",
"left_control",
"left_option",
"left_shift"
],
"optional": [
"any"
]
}
},
"to": [
{
"key_code": "right_arrow"
}
],
"type": "basic"
}
]
}Remapping my Existing Shortcuts
While I have built a lot of muscle memories in the past to control all this stuff with various modifiers, the Hyper Key removes a lot of the conflicts with other programs.
My current config (set in the particular programs):
hyper + up / down / left / right: Moving windows to the left / right halves of my screen, and to maximize and restore the windows using BetterTouchTool.hyper + t: Toggling the iTerm hotkey windowhyper + m: Toggling mute with Mutifyhyper + .: Open the Things Quick Entry windowhyper + c: Open the Clipboard History in Alfredhyper + p: Open 1Passwordhyper + a: Connect the Airpods with Toothfairy
Update: I was running into issues with the hyper + . shortcut. Turns out this combination is already taken by the sysdiag of macOS. I added a post on how to remap those.
Switching Keyboards and Layouts
For the past nine years, I have been using the various versions of Apple's external Magic Keyboard with a German keyboard layout and was pretty content with them. Even on the MacBook Pro I didn't experience the Butterfly keyboard as bad as its general reputation.
But being as easily tempted by new gadgets as I am, one topic got me curious over the past few months: Mechanical Keyboards. To test out these water, I gave in to this craving and bought a Keychron K2. And while I was at it, I also opted for the US layout to give it a try.
These are my first impressions three weeks in.
Keychron K2 - A Quick Review

For a lack of proper comparison I will keep my thoughts on the keyboard short. My main reasoning for this model was the relatively standard layout, the good macOS support with bluetooth and also a bit the price.
- It's a very different typing experience. I tasted various switches briefly and settled on the Gateron Brown ones. I'm still in the learning phase to figure out how much force I must apply.
- Bluetooth and battery are nice. No drops in connection; switching devices works well; only one recharge since I got it.
- It seems odd that they put a
ctrlkey to the right of the spacebar instead of anoptionkey.
I resolved the last point by remapping right_ctrl to right_option using Karabiner Elements — A nifty tool to do all sorts of funny things with keyboards.
Switching to the US-Layout
The switch from a German ISO layout to the US ANSI layout is a much harder topic. I'm currently probably at around 75% in terms of accuracy and speed. In particular the special characters still give me quite some trouble. That being said, I see now where a lot of the shortcuts in developer tools and the syntax of some language constructs are coming from.
A very specific topic: Umlauts. I'm still writing a lot in German as well, so the absence of Umlauts is actually a handicap. Long-pressing the bare characters until macOS' character picker appears is a no-go. Looking at alternative layouts, I started out with using the EurKey layout which adds all sorts of special characters with the option and option+shift modifiers. However, it broke all the regular characters usually reached with these modifiers, in particular I noticed it on the en and em dashes missing.
In the end I settled on the USGerman Keyboard Layout which only adds the umlauts. It's a huge timesaver and I cannot recommend it enough to anybody writing in English and German.
A First Summary
Using this mechanical keyboard and switching to the US layout surely won't make me a better typist all by itself. So, I'm not sure if there are enough benefits warranting all of this but it is a nice experiment and the novelty makes it pretty exciting for now.
And the overall topic already led me down the next rabbit hole: Setting the caps lock as Hyper Key and configuring all sorts of shortcuts. But that's for another post.
Node.js Best Practices
I only learned about it on the latest episode of the JS Party podcast: The Node.js Best Practices repository is a compilation of — you guessed it — best practices for developing services in Node.js. I'm happy this exists. It codifies a lot of the "feelings" and opinions I have on what is good code and which directions a code base should go. There are also quite a few things that I didn't bother so far. Looking forward to bring some new things into projects I'm working on.
Increasing the Fun in Video Calls
Working from home and spending a lot of time on video calls, got me wondering whether I could set up a system to have some sort of videoboard: Being able to have reaction-gifs or small clips playing on my video feed.
This is my quick documentation on how I set everything up (targeted to macOS, but should work similarly on other platforms).
What you'll need
OBS as Video Source
OBS is mostly known in the context of streaming your gaming or coding. But only very recently the obs-mac-virtualcam became stable enough so you can use the output of OBS as a webcam in other programs [1].
So with OBS and the virtualcam plugin installed, you can start OBS and already add your webcam (Video Capture Device). Then select Tools > Start Virtual Camera from the menubar and you can already use it in your next video call.
Adding Clips as Scenes
So go ahead and download your favourite short video clips from Youtube (easiest with youtube-dl) and drop them into new scenes in OBS (you might have to resize them to fill the whole screen).
At this point you can already cut between the different clips and it is shown on your video feed. However you always have to manually switch back to camera feed. Advanced Scene Switcher to the rescue: Under Media you can create automations to switch back to the camera whenever a media file has ended.

Audio
So the video part is ready to go, but how to rick-roll your colleagues without sound? BlackHole allows us to pipe sound from one program to another. So we want to have OBS output all necessary audio signals to BlackHole and then use BlackHole as audio input in your video conferencing program.
We're going to use the Monitoring functionality and set BlackHole 16ch as Settings > Audio > Advanced > Monitoring Device. Additionally we must also output the microphone to the monitoring device.
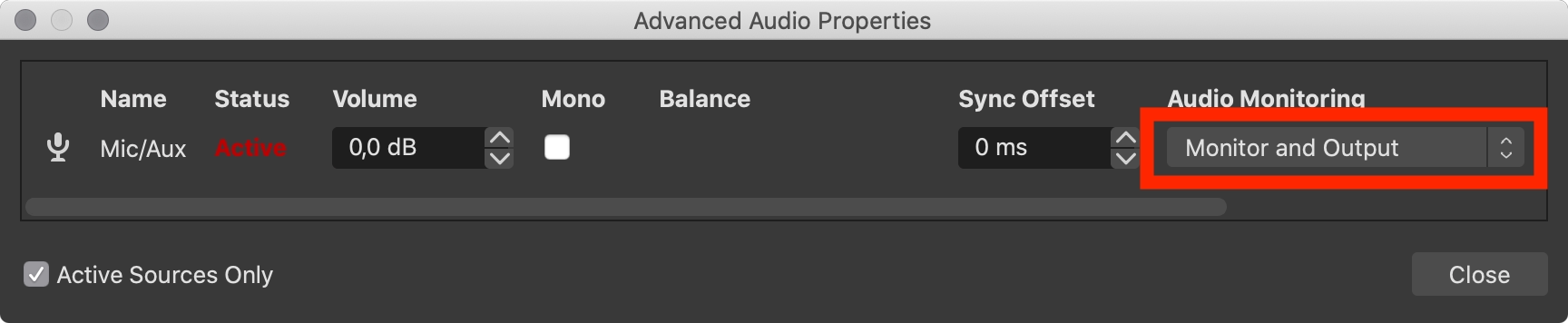
All that's left to do: Use the BlackHole audio device as microphone input in your video tool. 🎉
Notes
- Sometimes I had only static noise on the
BlackHoleaudio device and had to restart my computer. So if you plan to use this setup be sure to give a quick test-run before you annoy everyone on the call. - You can also set hotkeys to switch to scenes – makes it much more comfortable to switch between scenes.
Support is still limited. But for Zoom or using the Browser is fine in most cases. ↩︎
macOS Wifi Woes
I spent a large part of the past year being annoyed at the Wifi connection of my MacBook: Every once in a while it would clearly drop all traffic for a few seconds while reporting that everything is fine. This is particular annoying when being on audio or video calls. It occurred once or twice a week but I couldn't reproduce it at will. So I set out on a pretty long troubleshooting journey that got me a few times on the brink of reinstalling macOS from a clean slate. In the end the fix turned out pretty straightforward and by writing this post, I hope to remember it the next time macOS has such hiccups.
The Solution
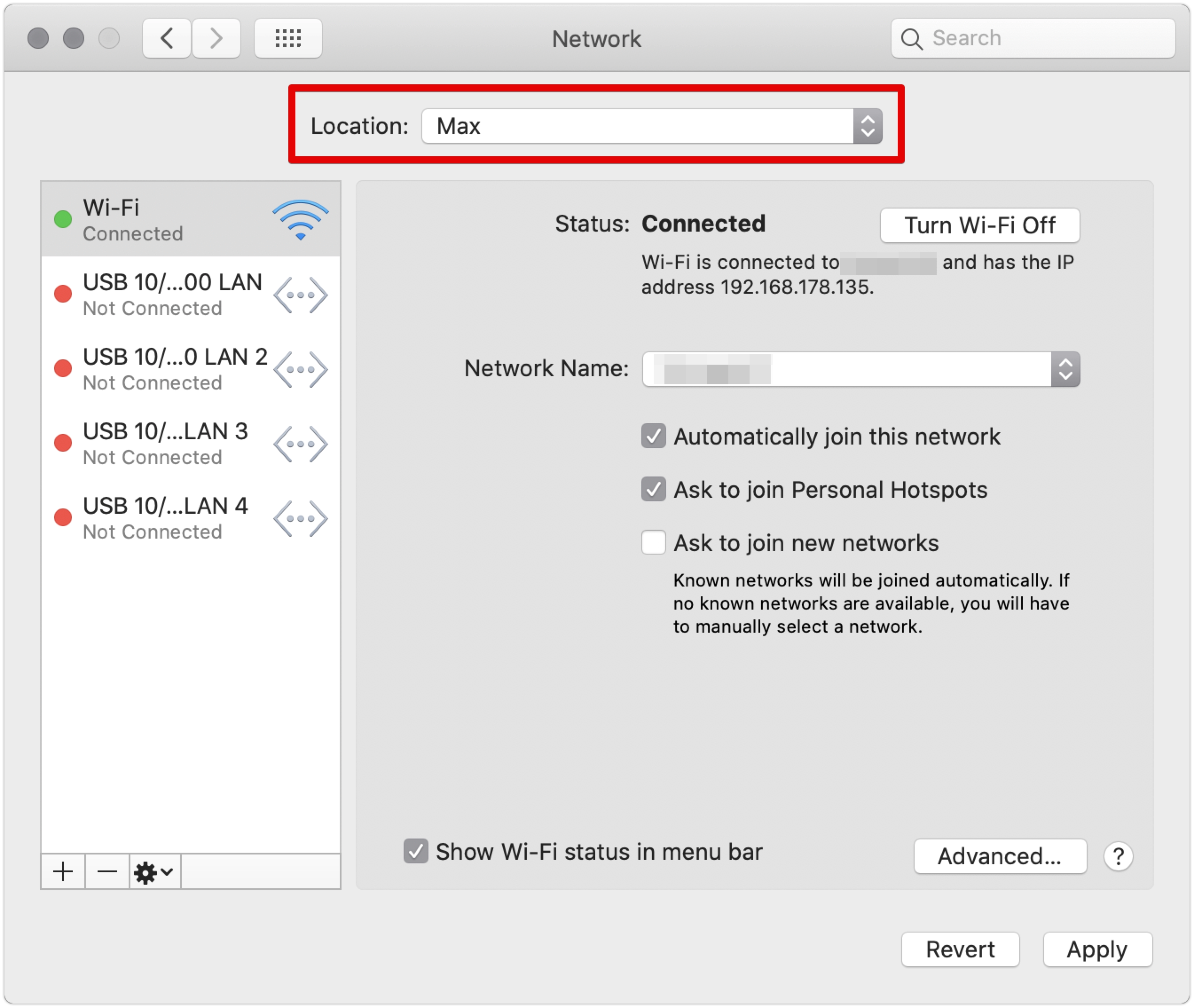
- Open Network Preferences
- Create a new Network Location and switch to it
- Reboot
- Connect to your network
- ...
- Profit!
Having done this a few month ago I never ran into the wifi drops ever since. 🤞
Other failed attempts
As mentioned, it was a pretty long time I endured this situation, but it wasn't for a lack of trying to fix it. Here a list of things that didn't work for me:
- NVRAM / PRAM reset: All time classic when dealing with issues on a Mac, sadly didn't bring any salvation this time.
- Changing Wifi Routers: Both at work and at home I was connected to Ubiquiti access points, so I assumed that maybe there is something afoul with this connection. But nobody else at work was affected, nor did changing back to an older Wifi-Router at home help.(And yes, I even fiddled with the MTU sizes, which brought back memories from LAN parties in the early 2000s)
- Removing the plist files: Nope, no improvements either.
- Running Wifi Diagnostics: Even when I was lucky enough to catch a dropout when running the wireless diagnostics, it wouldn't list any issues.
Working from Home: Audio Edition
Spending a good amount of my days in calls nowadays, audio quality is quite important. I have a plethora of headphones so I can comfortably listen to others on calls, but figuring out how to sound my own best is a bit more tricky and pretty much an ongoing process. Currently I settled on the microphone of the external webcam together with krisp.ai.
I have been content with the quality of using either the Bose QC35 or the AirPods via Bluetooth for calls so far. But when we as a team at work decided to gather in a permanently open Mumble room[1] things got a bit more tricky: Having the microphone channel open, everything switches to the low-quality low-latency SCO codec. This makes listening to music and any other media rather unpleasant.
So I started fiddling with other options to split microphone input and audio output. The microphone on the MacBook quickly showed that it's too much dependent on my relative position to it and even worse that you could hear the fans spinning up. So I was left with the external webcam I use, a Logitech c920. While I would say the sound itself is okayish it had a pretty bad echo. A colleague described it as preaching in a church. Having read about krisp.ai[2] earlier I gave it a shot, and lo and behold I'm impressed: It completely removes the echo and also filters out much of the ambient noise from traffic, most typing, and similar things. So I don't have to do the mute-unmute-dance after every sentence anymore.
Here are two audio samples:
-
Without krisp.ai
-
With krisp.ai active
For now I'm quite happy that I can listen to music and chime in on Mumble (and Zooms) without having to reconfigure everything all the time. Nonetheless I'm already prying on a dedicated microphone as it looks like the work-from-home situation will continue for months to come.